The building of change data capture (CDC) and event based systems have recently come up several time in my discussions with people and in my online trawling. I sensed enough confusion around them that I figured this was worth talking about here. CDC and event based communication are two very different things which look similar to some extent, and hence the confusion. Beware – using one for the other can lead to very difficult architectural situations.
What are these things?
Change Data Capture (CDC) typically alludes to a mechanism for capturing all changes happening to a system’s data. The need for such a system is not difficult to imagine – audit for sensitive information, data replication across multiple DB instances or data centres, moving changes from transactional databases to data lakes/OLAP stores. Transaction management in ACID-compliant databases is essentially CDC. A CDC system is a record of every change ever made to an entity and the metadata of that change (changed by, change time etc).
I have written about events on this blog before and have described them as announcements of something that has happened in the system domain, with relevant data about that occurrence. At a glance, this might seem to be the same as CDC – something changes in a system and this needs to be communicated to other systems – which is exactly what CDC is about. However, there is a key distinction to be made here. Events are defined at a far higher level of abstraction than data changes because they are meaningful changes to the domain. Data representing an entity can change without it having any “business” impact on the overall entity that the data represents. e.g. There can be several sub-states of an order that an order management system might maintain internally but which do not matter to the outside world. An order moving to these states would not generate events but changes would be logged in the CDC system. Vice-versa, there are be states that the rest of the world cares about (created, dispatched etc) and the order management system explicitly exposes to the outside world. Changes to or from these states would generate events.
The difference can be stated explicitly in terms of system boundaries. When we design microservices or perform any system decomposition, we are trying to identify and isolate bounded-contexts or business domains from each other. This is the basis of all domain-driven design.
CDC is about capturing data changes within a system’s bounded context, usually in the terms of the physical model. The system is recorded changes to its own data. Even if we have a separate service or system which stores these changes (some sort of platformized audit store), the separation is an implementation detail. There is a continuity of domain modelling between the actual data and changes to it, hence both belong logically inside the same boundary.
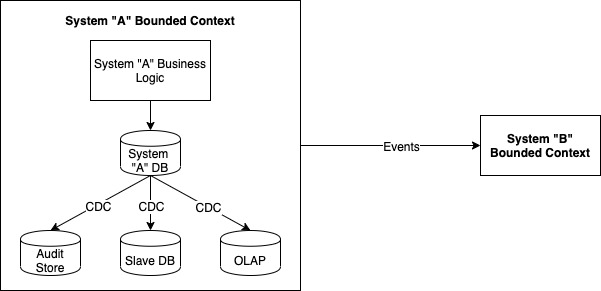
Events, on the other hand, are domain model level broadcasts emitted by one bounded context to be consumed by other bounded contexts. These represent semantically significant events in a language that the external systems can understand and respond to. That they are published over the same messaging medium, use similar frameworks, maybe get persisted somewhere etc are all implementation details.
What about CQRS
What about building a CQRS style system? For the uninitiated, CQRS (Command Query Responsibility Segregation) is an architectural style where the data model and technologies used for writes (Command) are different from those used for reads (Query). Such a design is typically used when there is a large difference in write patterns and to be supported and the read patterns to be supported. I have given a brief example of such a system in my case study on the nuts and bolts of using asynchronous programming. Updates to the command model and propagated to the read model, typically (but not necessarily) asynchronously. Can we use CDC for this? or should the command module emit events that are read by the query module to build its data model?
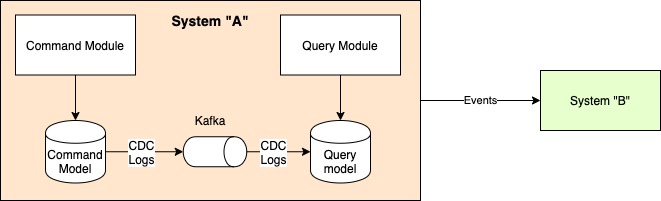
I would argue that since the command-query model separation is the internal design of the system, both models lie inside the same bounded context, and using CDC logs would not be inappropriate. Both producer and consumer are at the same level of abstraction (both are data stores, though one may be MySQL and the other ElasticSearch), so using DB level changelogs is not a bad idea. This is, of course, just an opinion. Using events here would not be bad either, especially if different teams manage the models.
The command module should always emit events anyway, if nothing else, then for lending evolutionary characteristics to the overall architecture.
Building CDC and Eventing Systems
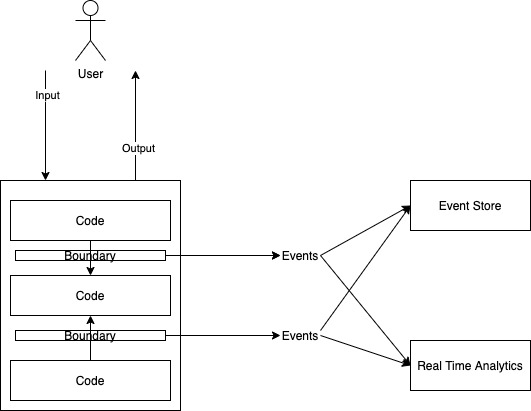
In modern distributed setups, change data is typically published over a messaging medium like Kafka and can then be consumed by other systems which want to store this data. A very popular and efficient way of building CDC systems is by using tailing the internal log files of databases (MySQL and other relational DBs always have this for transaction management, ElasticSearch has a change stream in its newer versions) using something like Filebeat and then publishing the logs over Kafka. The other side typically has Logstash type plugins to ingest data into another system which persist this changelog. Consumers may also be Spark/Flink style streaming applications that consume and transform this data into a form suitable for other use cases.
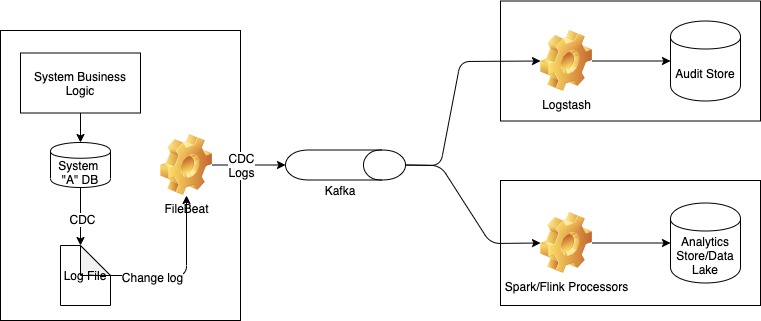
This is obviously not always possible since not all databases have changelog files to stream. For these systems, we must resort to adding code to the application layer itself to emit the changelog. Making sure that there is no case where data gets changed but the log is not emitted is a very hard problem to solve (essentially an atomic update problem: how to make sure that DB update and event emission over Kafka both happen or nothing happens). Lossless-ness is critical in a CDC system.
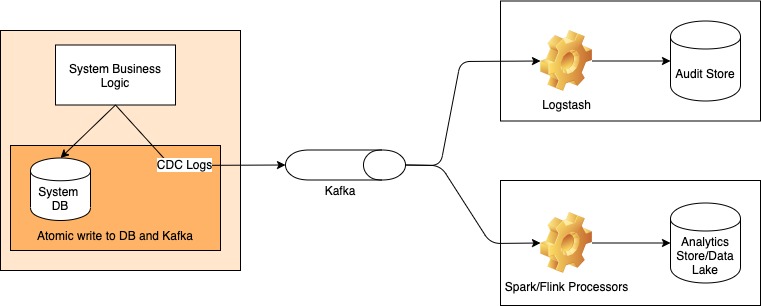
To build an event-based system, we would have the event generation logic at the applications layer like we did for CDC in the case of databases that don’t have log files. That is the only place where we can translate the language of the database to the language of the domain. Same as for CDC, preventing event loss in the publisher is key to the design.
However. some people propose to use the CDC stream as a system’s event stream, and this is where I completely disagree due to all the reasons I have mentioned above. This would couple other systems to our system’s physical data model, and we would have to forever keep our public entities the same as the database model. This severely reduces the expressiveness of our domain model. Consider an order getting canceled. The CDC system will record something like
ChangeLog{“order number” : “12345”, “changed field” : “state”, “old value”: “in progress”, “new value” : “cancelled”}
If I were to express this in my domain language of what can or cannot happen to orders, I would ideally something like
OrderEvent {“order number” : “12345”, “event type” : “order cancelled”}
But this abstraction would just not be possible if we physically couple the language of transmission to CDC language.
Summary
One of the things to remember in building software is this: sometimes things that look similar and use similar tools to function are not the same. Especially when working with logical and physical models, we should be careful to isolate the implementation detail from that which is being implemented. Look hard at the publisher and consumer of the record that we are publishing – if they are both defined at the “data store” level, we are probably talking CDC. If that more of business constructs (bounded contexts) like order, courier, invoice etc, we are likely in events-ville.
Read Next : Messaging terms defined precisely
If you liked this, subscribe to my weekly newsletter It Depends to read about software engineering and technical leadership


Nice read – I was thinking in similar directions, but with a focus on erroneous updates and inserts.
Consider a source system into which by accident sensitive or wrong data was inserted. In case of CDC you cannot distinguish between good and bad events – everything gets captured and forwarded.
On the event level / service layer however, you can
a) delay emits of events. This could decrease the probability that bogus data gets streamed to downstream systems.
b) design events that explicitly notify downstream systems about bogus data they have received before.
While it is true that “What has been seen cannot be unseen”, one can at least inform the downstream systems, that they should forget about something. Implementing such a requirement leaves the scope/domain of CDC entirely.
It boils down to the fact, that there can be different types of changes in the source system:
– The normal domain changes including the transitions and known error modes (order cancelled, money transaction rolled back, …)
– Out of domain events such as “Oh shit I accidentally published something I should’t have”. Where e.g. test data was accidentally put into the system, which then pollutes the downstream systems. While this should not happen – it might and depending on the business, it might happen regularly. For those cases you might need a “recall event” button that signals the downstream systems to “forget the nonsense”…
Anyways – your article really helped me understanding the requirements in our current project, so thank you very much!