Hello Folks!
I am starting a new series of articles called “For the Layman” to cover some frequently encountered software engineering concepts to non-developers or beginners. The articles with try to explain these concepts in simple terms with as little jargon as I can manage.
In this first episode of the series, let’s understand “distributed systems“.
As the name suggests, a distributed system is a “system” whose components are”distributed“. Let’s look at both those words individually.
What is a system
A “system” is a set of parts working together to deliver a certain functionality. A clock is a system of springs and gears that tells time reliably. A car is built up of many parts which allow us to be driven from one place to another. Let’s call each part a “component”.

Monoliths : “Not” distributed systems
Most mechanical systems are not, and cannot be “distributed”. Components in most hardware systems assume “local” availability of their partnering components. Piston rods expect to be welded to crank shafts, keyboards expect to be connected to processors etc etc. A software system built along these is sometimes called a “monolith”.
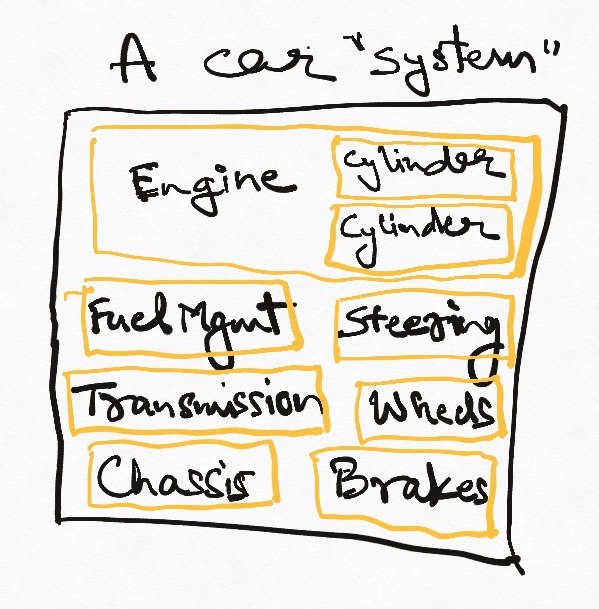
Vertical Scaling
A side effect of having to put all components next to each other is that to build a more powerful system, we need to fit more pieces on the same chassis (so to say). If we want to add more engines so our car can go faster, we need to add a larger engine with more cylinders. This in turn requires a large car, and so on.

You can also think of trying to add more power to your laptop by adding more processors or more memory. It can be done but makes the laptop larger and larger – eventually we end up with a desktop rather than a laptop. This process of adding more and more power to a single physical system is called “Vertical Scaling”. It is an important strategy (Moore’s law is essentially about vertical scaling), but comes with hard physical limits that are very difficult to surmount.
Location Coupling
Mechanical systems also assume a certain “guarantee” in terms of collaborating with each other. No unreliability is expected between the turning of a gear and the turning of the clock hand (there may be errors of precision, but that is not the question here). A clock is designed with the assumption that certain things will cause certain other things to happen, and if they don’t then the clock is considered broken. The functioning of the complete system depends strongly on all of the components always being physically present in a certain location at a certain time. This type of dependency pattern is called a form of “tight coupling” between components.
Globally Consistent State
This hard dependency on all parts strictly working together has an interesting implication. It means that if we know what state (e.g. position, location) one component is in, we necessarily also know the states of all other components. If component A is not in the position that component B expects it to be, then we have a problem. As a result, our knowledge of the system at any point of time is complete and consistent. This is called “Globally Consistent state” or just “Consistent State”.
As you may be able to see by now, it is difficult to build very large systems when everything MUST be co-located and MUST work all the time. A large system built using these principles is brittle – any small failure can cause a complete outage. It is also not scalable – as the size grows, not only do we have to keep fitting everything next to each other (imagine an engine with thousands of cylinders all of which must be next to each other and must coordinate completely), but we also have to have complete knowledge of all component at all times to be able to understand if the system is working properly. The cognitive load such a system creates is tremendous and increases exponentially with every new component.
Modern software architecture is as much about handling unprecedented scale as it is about solving business problems. Whether it is the billions of people using Facebook or the surges of online shoppers on Singles Day, software systems today are expected to deliver tremendous performance and continue to function even when parts fail. To fulfil these requirements, distributed systems have emerged as an alternative paradigm for constructing systems built out of many components.
What is a distributed system
Server : A computer connected to the internet or some other network.
Distributed systems are made up of “independent” components which are not necessarily located next to each other.
This seemingly simple definition of distributed systems has huge ramifications and gives these systems their unique strengths and weaknesses. Let’s cover some of these in detail.
Location Transparency
Components in a distributed communicate with each other via methods/protocols that don’t require the calling component to know where the called component is located. So the engine can potentially be located at home even when you drive your car. Somehow when the accelerator is pressed, the engine generates more power which is somehow transferred to the wheels. Another analogy is the remote working style we now see everywhere. Team members are not physically located together, but still cooperate by performing their respective jobs in benefit of a shared objective.

This is called “Location Transparency” which is a form of “Loose Coupling” (all developers get a dreamy eyed look when they hear this word – try it!)
The advantages of location transparency are obvious. If software components need not be co-located, then we can move them to different physical machines, each of which can then be vertically scaled. i.e. We can buy powerful machines for each component separately instead of fitting all components on one machine. This directly leads to a more powerful system. Note that we are not “mandating” that components must be located on separate servers, just that it shouldn’t matter where they are located as long as there is a way to locate them.
How do these distributed components find each other? There are many ways to do this. One of the most popular mechanisms is DNS (Domain Name System) which maps names to IP Addresses (unique identities of servers all over the internet). The backbone of all networking is the ability to locate one specific machine given its IP address or domain name. This seemingly small (but actually extremely complicated) technique has allowed software to eat the world.
Partial Failure Mode
A fallout of the distributed nature is that our failure mode is not all-or-nothing anymore. The “card reader” component may have failed but the account management component may be running. This means that some functionality related to account management may still be accessible even though our card swiping users are frustrated.
Horizontal Scalability
Yet another corollary of location transparency is that there need not necessarily be only one more instance of a component. If it doesn’t matter where the engine is located, we can now add ten or more independent engines to add that much more power.

It is even possible to add and remove engines from the car as needed. This ability to add more instances of a component is called “horizontal scaling”, and is the currently preferred mechanism for scaling software systems since it bypasses the physical limitations of how powerful a single server can be – we just add more low power servers to compensate.
So we have a bunch of components living on different “servers” (machines) and communicating over a “network” (internet/LAN). Is that it?
Eventual Consistency
There is one more interesting thing to understand here – The network is unreliable and slow.

If your Zoom call has ever hung mid-sentence or Youtube has “buffered”, you know what I’m talking about. Data is sent from one component to the other, but sometimes doesn’t reach it or reaches after some noticeable time. Maybe the wire is cut, maybe the other component reads the data but crashes before it could do anything with it, maybe a lot of data was flowing over the wire and hence everything is stuck.
Any which way this occurs, this results in different parts of the system not having complete information about each other. This happens all the time in the systems we encounter on the web – payment was taken but order could not be placed (payment component is not able to talk to order component), money transfer is triggered but will reflect in 24 hours (transfer component know that there is to be a transfer but the account component has not been told yet).

Another way of putting this is to say that the independent components of a distributed system understand their own “state” (e.g. position, orientation, amount of load) absolutely but may be out of sync (to a greater or lesser extent) with other components. The “out of sync-ness” is a result of the network acting as a queue of unshared knowledge between them.
This is called “inconsistency” and is the other side of the Global State we encountered in non-distributed systems. The remedy for this in distributed systems is “Eventual Consistency“, meaning we must implement mechanisms which will ensure that all components “eventually” agree with each other on what the overall state of the system is. Note that this is a catchup game, and components are out of sync-by-design rather than by mistake. This gives us some buffer time in which we can perform knowledge transfer instead of making every component aware of everything instantaneously (a physical impossibility in the distributed world given that nothing can travel faster than speed of light).
The bad parts
While distributed systems can be extremely resilient to failures and very responsive under high loads, building well designed distributed systems is an extremely complicated undertaking.
The first problem is user experience. There is no way to hide the eventually consistent nature of the system from the users. With instant gratification being the increasingly accepted norm, it can sometimes take a lot of clever UX to keep the system distributed and the user happy.
Distributed system is necessarily much more complicated than a “monolithic” (everything in one place) design to compensate for the fallacies of distributed computing. A lot of new tools have evolved to help developers build reliable distributed systems, but this is still far from an easy or solved problem.
I hope you got a basic understanding of distributed systems from this article. If you are a beginner and found that parts of the article were still too technical to understand, let me know in the comments and I will try to break things down in simpler terms.
The “For the Layman” series will try to explain deep software engineering concepts in very simple language. Sign up to the mailing list (bottom of this page) to receive the next episode right in your inbox.



Hello Kislay,
I came across your blog via https://news.ycombinator.com/ just today, and I love your writing! I will say more later, but for now I have a quick question – can you recommend any good books on distributed computing, from the perspective of someone who has quite a bit of experience in Python, but little in distributed computing?
Many thanks!
David
Hi David. Thanks for your note – glad to know that you liked the article.
Some books that come to mind readily are “Domain Driven Design” by Eric Evans and “Designing data intensive applications” by Martin Kleppman.
Domain Driven design covers what can be considered the heart of microservices – discovering boundaries in your systems and strategies to implement those boundaries.
https://www.amazon.in/gp/product/B00794TAUG?ie=UTF8&tag=kislayverma-21&camp=3638&linkCode=xm2&creativeASIN=B00794TAUG
Designing data intensive applications looks more technically at application design which need to move data around and the consideration in designing them.
https://www.amazon.in/gp/product/9352135245?ie=UTF8&tag=kislayverma-21&camp=3638&linkCode=xm2&creativeASIN=9352135245