What should be the discount offered for Nike shoes or on Nike running shorts if the customer is a high value customer versus a new comer to the system?
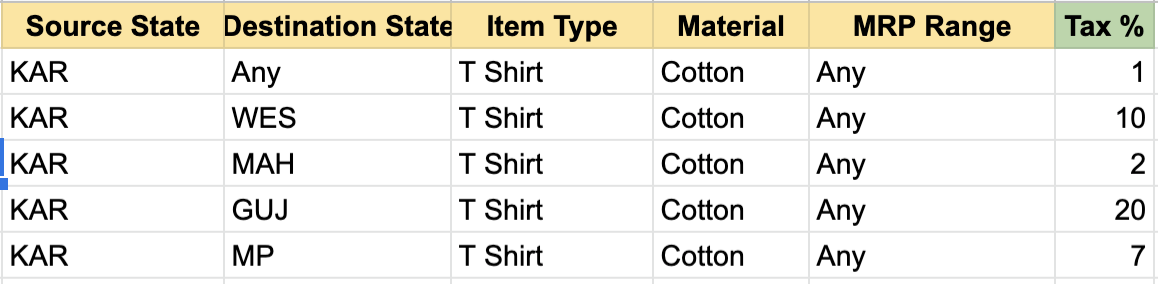
What is the applicable tax rate if a cotton t-shirt is made by manufacturer in a state and sold in another state?
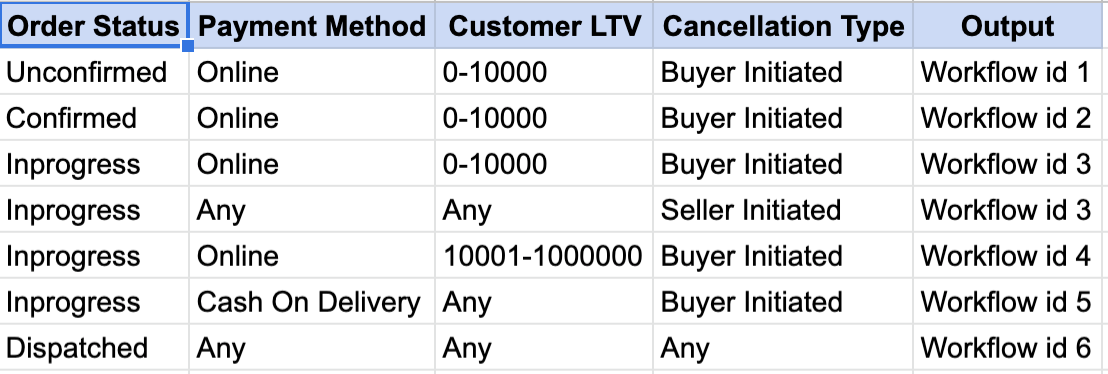
Which customer care agent should a call be routed to if it relates to an already escalated issue by a customer who only speaks Hindi?
Situations like those described above are no doubt familiar territory to any software engineer. Much of everyday software engineering is the codification of these types of rules in programming terms and then keeping up with the constant evolution that the business wants to do to them. And as you might imagine, a variety of tools have sprung to help programmers solve the problem.

As a general class of software, these tools are called “Rule Engines” or “Rule Systems” and play an important role in business rule management. They are available in most programming languages and offer a variety of ways of achieving rule management. The big daddy among them all, without a doubt, is Drools, which offers extremely powerful, rule modelling, management and evaluation capabilities. No matter how how complicated the rule set, there is probably a way to do it in Drools.
So why did I build Rulette? What is Rulette, you say? Rulette is my first open source project that I have been working on (fitfully) for the last 6 years. From the Wiki:
Rulette is a lightweight, domain-agnostic rule modelling, storage, and evaluation engine.
I’m going to do this vis-a-vis Drools because it is THE most feature-complete rule engine out there, and also because looking for Drools alternatives is what actually drove me to creating Rulette. I will cover why I think Rulette is a better (at least simpler) alternative in most cases, but I will also talk about When Rulettte should NOT be used.
Business rules usually aren’t that complicated
Drools’s DSL offers extremely flexibly ways of modelling very complicated rules. Hell you can actually write java code inside the DSL to tackle the most difficult use-cases. Why would we give up this superpower?
While product managers would like us to believe that the rules governing a business can get insanely complex, “typically”, this just isn’t so. The people running the business have to be able to make sense of what happens when, and an over-complicated set of rules just isn’t practical in doing so. Most time, the rules can be expressed in a spreadsheet! A few columns each representing the inputs, mapping to another column which states the output. Anything more complicated than this is more exception than the rule.
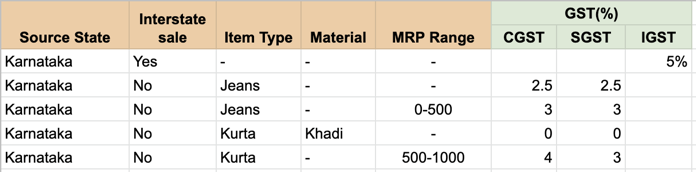
So it turns out that we don’t really need the super awesome modelling power of Drools. For most of your needs, the requirements reduces to a series of “AND” conditions and and handling the “Any”/”Other”/Default use-case. Rulette does exactly this in a simple and efficient manner. Each rule is a series of “AND” conditions on the rule inputs and the entire set of rules is arranged as a trie for efficient lookup.
End to End Rule Management
While we typically won’t need the extreme flexibility offered by Drools, we still need to “manage” the rules – create them, store them, update them etc. Drools has out of the box capabilities for doing these admin activities, but it has its own storage format and quirks to go with it. Most other rule engines don’t even come with these capabilites – they focus more on rule evaluation to determine the output and leave out the rule administration.
I wanted the best of all of these, so Rulette not only evaluates the output using a given rule set, but also has built-in rule management (CRUD) APIs. You can create new rule, update them, read them etc in the same consistent way that you use to evaluate them. This also allows Rulettte to enforce consistency checks on rule semantics (e.g. don’t create the exact same rule twice) in-band to prevent any data corruption which may happen if you were to manage the rules outside of Rulette and then try to load them.
Rulette also comes with a plug-and-play storage SPI that can be implemented for any data store. As long as you implement the data layer interface exposed by Rulette, you can store your rules in whatever datastore or manner you want. This last is important because often when a rule engine is being introduced into an existing application, the rule-set already exists in some shape or form and it is not alway possible to change that storage. But it is almost always possible to write a new adapter between the data and the Rulette rule format and get started.

I started off by completing a MySQL implementation (thats the store I was working with), but I have since seen a JSON file based implementation, a Redis backed implementation, and even a REST API backed implementation of rule storage (this team couldn’t access the data directly, but had access to the APIs around it).
Talking business language
The way Drools models rules (Each rule is broken down into a tuple of key-value combination of rules input names and values) does not translate easily to business speak – I found that explaining any errors that arose in the application was kind of difficult without using specific additional tools/UIs. While I do not believe that having “users write the rules themselves” is practical or even desirable, I do feel that having minimal impedance mismatch between rules makers and rule implementers can help the dialogue.
So I wanted Rulette to align the business team’s mental model of their rules and the way the developers do the technical modelling. So I explicitly designed the rules domain model to be tabular and having data types and ranges as first class citizens. These are the most widely used constructs in defining rules, and having these capabilities out of the box help in talking about things like price, date, discount natively.
This is a design choice that, in my opinion, makes things simple for everyone. Several times, we were able to directly ingest/export excel sheets into our systems and analyze the input and output validated in a very intuitive manner.
Simple setup, High Performance
Using Drools involves setting up a server and having your applications connect to it in a specific manner. For many use-cases, this is too elaborate a setup. Rulette simplifies this, at least for Java based applications, by being implemented as an extremely lightweight library (no external dependencies except joda-time) which loads the rules in-memory. This make the rule evaluation process simple and super fast – You can get hundreds of thousands of evaluations done per second since each one is just a trie-traversal.
What next
Right now, Rulette is a useful library for implementing and managing your business rules. But there are some things that will make it even more enterprise-friendly.
Distributed Rulette
The single biggest room for improvement that I see today is that Rulette only works on one machine. This has two adverse results. One is inconsistent data in distributed setups. e.g. If your service uses Rulette internally, all instances of the service will have their own in-memory version of the rules and they might go out of sync if any rule is updated – there is no way to keep the distributed setup in sync. The only way to do this today is to periodically reload the rule-set on all machines. Essentially Rulette is acting like a local cache instead of a distributed cache.
The other manifestation of the problem is that we are limited by the number of rules that can be loaded in memory of a single machine. A more distributed version of Rulette would be able to store and evaluate rules across multiple servers.
Server
Rulette server is an attempt to make Rulette’s capabilities available to non-Java applications. There is already a Rulette server available, built on the RestExpress framework which exposes the rulette APIs over a REST interface. But both the design and the API leave much to be desired.
UI
Everyone loves a good UI – and Rulette doesn’t have one today. A good admin UI to visualize and administer rules would make Rulette a very attractive proposition indeed.
Caveat Emptor
If you truly are in the unfortunate situation of having more complicated rules that a series of AND conditions can’t express, you have my sympathy – I and Rulette cannot help you.
Also, if your rule-set is so large that it cannot fit in memory on a single machine, you cannot use Rulette. This problem is easily to solve by adding more memory, and I haven’t actually seen this in the wild.
You can check out a talk I gave (deck) and the project Wiki to get more details on the internal architecture and the way rules are evaluated. I have also written a case study of using Rulette to model taxation rules. I would love to hear your thoughts and suggestions about how we can make Rulette even more awesome. Contributions to the code are welcome. Please reach out to me in the comments below if you want to learn more about use-cases or if you have any questions.
I hope that when next you come across a reason for using a rule engine, you will remember Rulette and spread the good word!
Read Next : More articles on Rulette